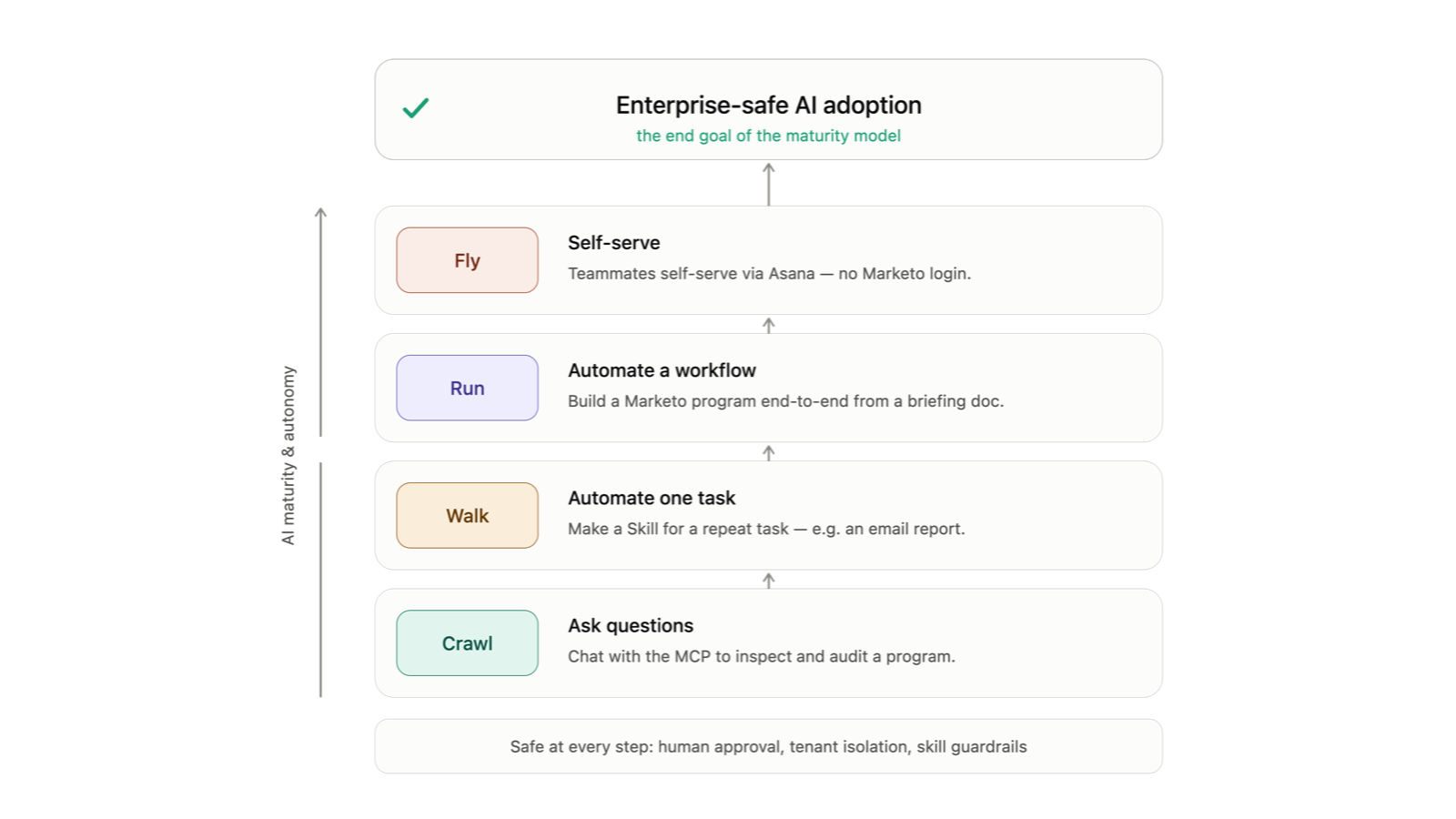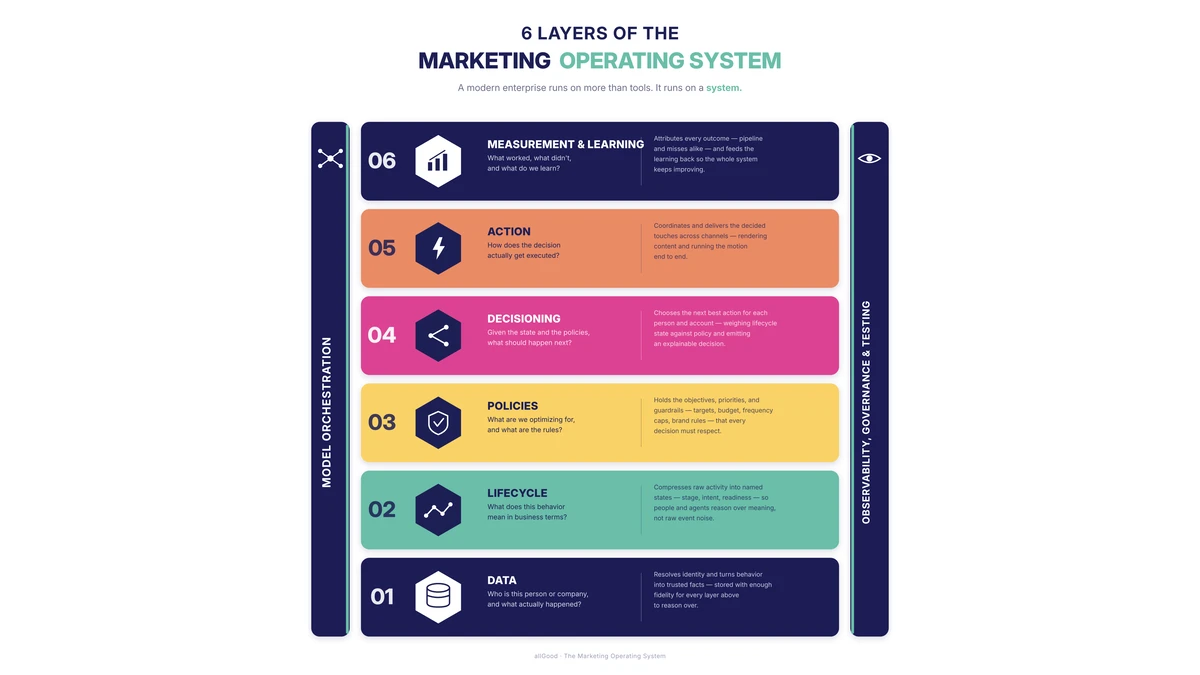
Last post we covered governance — what an agent is allowed to do. This one is about what happens after you press deploy. How you see what it's doing. How do you know when it goes sideways? How you recover when it does.
Whether you're building your own agent or evaluating a solution, this is the discipline that separates the demo from the system that runs your pipeline next quarter.
That trust does not come from the agent being smart. It comes from two old, slightly boring pillars: testing and observability.
But do we really need testing and observability?
Some of the most credible AI engineering teams in the world have already answered that question:
Anthropic, in Demystifying evals for AI agents, puts it plainly — "Without [evals], it's easy to get stuck in reactive loops—catching issues only in production, where fixing one failure creates others."
Microsoft, in Applying SRE to Autonomous AI Agents, is even more direct — "running agents in production without [Agent SRE] is the equivalent of running a fleet of microservices without circuit breakers, health checks, or an on-call runbook."
The people who make the models and the people who run them in production are telling you the same thing from opposite ends.
For CMOs and marketing leaders: your traditional SaaS tools were built on rules. They were constrained in what they could do, but they failed in deterministic ways — and over two decades we built practical ways to manage that. Agentic systems don't fail like that. So we need a new generation of the same practical discipline, and you do not need to invent it. The people building the agents have already written the playbook.
Three simple problems to consider
1. You can't fix what you can't see
Sounds really simple, to figure out problems, you need to see what it did, and in a normal app, observability is logs and metrics. Did the API call work? How long did it take? But in the new agentic workflows, "what happened" is a chain. You have to think about the prompt, what context it had, what reasoning it did (which is not always visible btw, but that's a separate post). The tool the agent picked. The parameters it passed. The next decision. And the one after that.
If you only log the final output, you're holding a result and a vibe. The agent did X. We think.
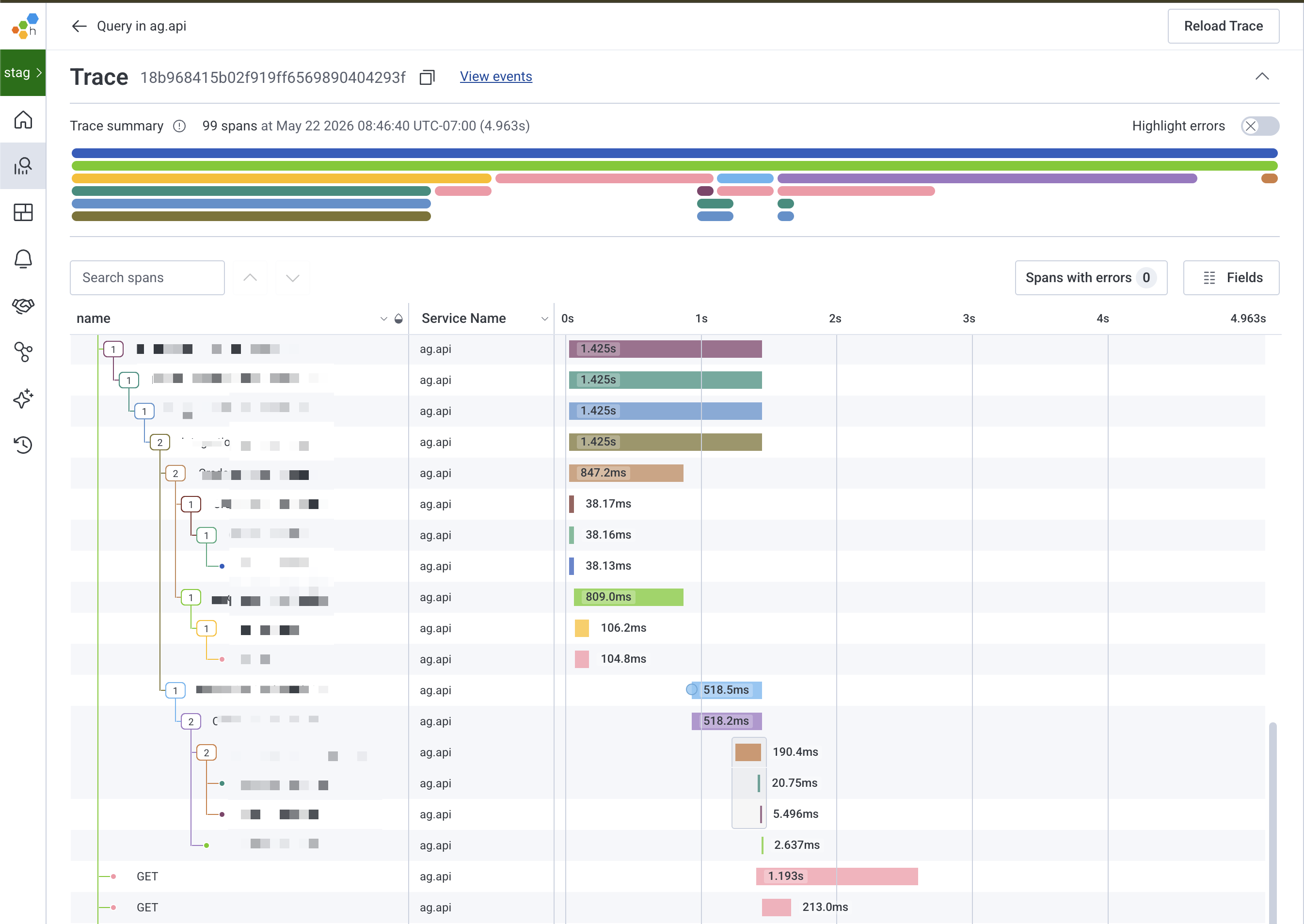 Honeycomb / LangSmith style traces let you see every step of an agent run — not just the final output.
Honeycomb / LangSmith style traces let you see every step of an agent run — not just the final output.
This is where observability comes in, so while it's important to make sure the agent works once, you have to think about putting in the work to make sure EVERY call, and EVERY trace that goes along with this is available so you can figure out problems when they happen.
2. Testing in a non-deterministic world
 xkcd nails it: when the answers look wrong, you just stir the pile until they look right.
xkcd nails it: when the answers look wrong, you just stir the pile until they look right.
Software testing assumes determinism. Same input, same output. Agents broke that on day one. You can't unit-test an agent the way you unit-test a function, you have to throw away your old playbook honestly, cause the same prompt, different day, maybe even the same input could give a different answer. Not wrong. Just different. The good news is, that we have a very clear solution to this problem: Evals — golden datasets, scenario tests, graders (deterministic or LLM-as-judge), scored across hundreds of representative tasks.
If your agent has never been measured this way, the demo is the product.
3. Don't trust the HTTP 200
This is the toughest one, cause we have to throw out all our traditional monitoring ideas! Getting a 500 was considered bad, you could think about it so cleanly. Agentic failures don't look like that. The agent returned a valid JSON payload, the rest of the system worked, all updates were successful, this is fine! Oh, only later might you get a call from someone in Sales or a Marketing Ops that we might have, just this once, hallucinated a campaign name into Marketo and came up with a totally random field value.
So what we end up having to do is build a new type of guardrail, you can't just assume the agent response being valid as JSON structure is enough, heck you cannot even trust if the API call to your downstream system working is really work, cause there is text fields that might not be getting validated the way you expected. Your users will notice, and they will call you, so you better have 1, and 2 in place to help figure out what happened, and then add another test case to keep learning and getting better!!!
And this is the kicker, your users, the ones that expect everything to work now also need to understand that this AI system can make mistake, it will learn and improve, and they have now become part of the system improvement loop!!
The mainframe people had a name for this
 The IBM System/390 — the era where "just refresh the page" wasn't a recovery strategy.
The IBM System/390 — the era where "just refresh the page" wasn't a recovery strategy.
There's a vocabulary for the discipline I just walked through. It comes from a less glamorous era — the people who ran mainframes, banks, payroll, booking systems. Places where "just refresh the page" was not an acceptable recovery strategy.
Three letters: RAS — Reliability, Availability, Serviceability.
- Reliability: the agent does the right thing consistently, not just on demo day.
- Availability: the workflow degrades gracefully when a model, API, tool, or data source fails.
- Serviceability: when something goes wrong, a human can inspect it, replay it, understand it, and improve it.
We're now letting agents make business decisions. Like the mainframe days, we should adopt the discipline and bring these three words back into our shared vocabulary — so you're prepared to solve problems when they happen, not if.
At allGood, we have been boring about these things from the start, partially because my mentors and early managers happened to have been from the days of the mainframe, and drilled these three words into me personally over the years. The tools we use are not the same, but it's the same patterns applied to a new problem — interested in chatting more about the details, hit me up!